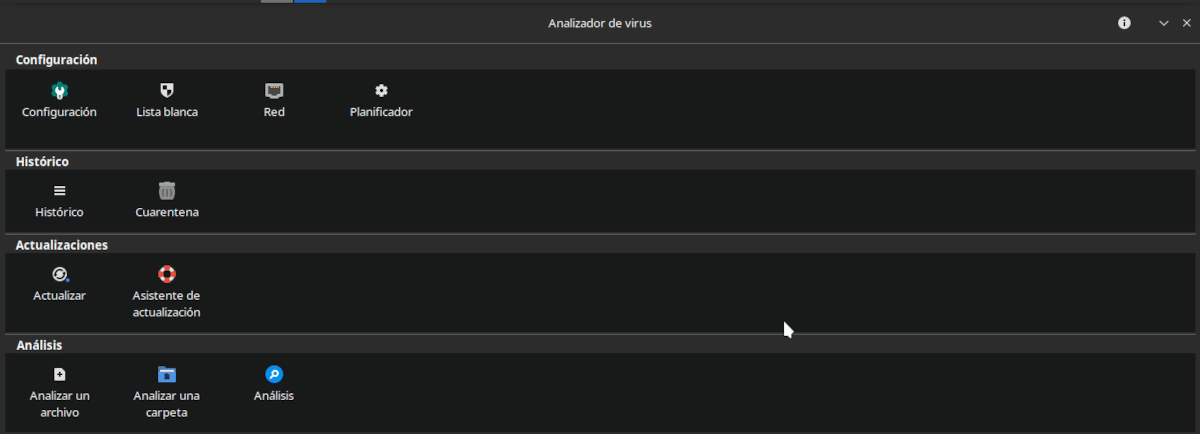
ClamTK es la interfaz gráfica para controlar el antivirus de código abierto ClamAV
(adsbygoogle = window.adsbygoogle || []).push({});
¿Los productos responden a una necesidad o la crean? Aunque el consenso dentro de la comunidad es que Linux no necesita un antivirus, alguien se tomó la molestia de desarrollarlos. De hecho, hay bastantes alternativas tanto gratuitas y de código abierto como comerciales.
En este artículo vamos a ver qué es ClamTK, la interfaz gráfica para ClamAV, una solución antivirus de código abierto y cuándo deberías instalarla.
(adsbygoogle = window.adsbygoogle || []).push({});
¿Necesitamos un antivirus en Linux?
Durante mucho tiempo los linuxeros nos convencimos de que éramos inmune al código malicioso. Sin embargo, en los últimos años debimos cambiar de opinión. Los ataques contra Linux vienen aumentando desde 2016 y casi un tercio del malware se dirigen a este sistema operativo.
En parte, este aumento de los ataques es porque grandes organizaciones se volcaron a Linux como un sistema fiable capaz de realizar tareas criticas para los servidores corporativos de manera más eficiente y a un menor costo que sus contrapartes privativas. De ahí que se transformara en un objetivo legítimo para los atacantes ya que los datos que almacenan y las redes que soportan son enormemente valiosos.
Algunas vulnerabilidades aprovechadas por los atacantes son:
(adsbygoogle = window.adsbygoogle || []).push({});
Uso de lenguajes multiplataforma
El uso de aplicaciones multiplataformas como las programadas en Java (que corre bajo una máquina virtual) es una fuente de entrada del software malicioso. SI estas aplicaciones trabajan con datos sensibles, no importa que sistema operativo estés utiizando.
Uso de gestores de contenidos
Linux es el sistema operativo mayoritario en servidores. Y en muchos servidores se usan gestores de contenido como Drupal y WordPress. Estas herramientas suelen instalarse con un alto grado de permisos incluyendo el acceso de escritura FTP. Para ampliar funciones, estos gestores de contenidos suelen utilizar complementos de terceros que suelen tener un alto costo por lo que muchos irresponsables suelen descargarlos de fuentes alternativas. Y, aunque se descarguen desde sitios oficiales no se pueden descartar errores de programación que causen vulnerabilidades.
Portador asintomático
No hay nada que impida que un ordenador con Linux contagie malware a sistemas vulnerables. Las computadoras con Linux reciben y envían correos electrónicos con archivos adjuntos que pueden estar infectados.
No estar al día con las actualizaciones
En el caso de servicios comunes como Apache y FTP, mantener una actualización periódica es tan vital como respirar para los seres vivos. Las actualizaciones periódicas reducen los riesgos, pero muchas personas a menudo ven estas tareas críticas como pérdida de tiempo e ignoran las notificaciones que les solicitan hacerlo. Otras veces es porque las actualizaciones obligarían a dejar de usar programas que dejarían de ser compatibles.
(adsbygoogle = window.adsbygoogle || []).push({});
Uso de Samba
Samba es una suite de programas que permiten integrar Windows y Linux en una misma red. Cuando se usa Samba, los recursos compartidos de Linux se ven y comportan como cualquier otro recurso compartido de Windows. Es decir que ya no funcionan los permisos de Linux. Las herramientas de seguridad de Windows no están preparadas para detectar software malicioso para otras plataformas.
Cuando se utilizan las herramientas de Windows para escanear el contenido de los recursos compartidos de Linux a través de una red se corre el riesgo de dejar el tráfico expuesto. En el caso de equipos usados en empresas, algunos de los ataques más dañinos fueron realizados por empleados descontentos que buscaban hacer daño o que buscaban obtener un beneficio económico.
Aumento de la complejidad del sistema
Con el uso de tecnología como contenedores y virtualización, es posible tener varias versiones de un sistema operativo o varios sistemas operativos instalados al mismo tiempo. Es por eso, que a menos que se tenga instalada una herramienta automatizada para gestionarlos, es imposible seguirles la pista a las actualizaciones. De ahí que aumenten los riesgos de seguridad.

A medida que las empresas confiaron más en Linux para su infraestructura, los atacantes lo convirtieron en un objetivo.
Mala definición de roles y privilegios
Linux tiene un claro sistema de roles y privilegios que deben ser cuidadosamente respetados. El usuario Root es el que tiene poder para acceder a cualquier lugar y hacer cualquier modificación dentro del sistema. Hay algunos usuarios que sin ser Root cuentan con los mismos privilegios.
Los usuarios normales tienen vedados el acceso a determinadas partes sensibles del sistema, pero, con respecto a las partes en las que tienen acceso existen también distintas restricciones a lo que pueden hacer.
La regla es asignar a cada usuario solo los privilegios que se necesitan, pero, porque lleva mucho tiempo, es complejo o no se tienen los conocimientos suficientes, muchas veces esas reglas no se respetan.
Falta de capacitación de los administradores de sistemas
Los administradores de sistemas capacitados no abundan y, son caros. Muchas veces se contratan a personas sin los conocimientos suficientes y que están sobrecargadas de trabajo. Aún en los casos de profesionales, suelen atarse a determinadas tecnologías sin verificar que sean las adecuadas en cada caso.
Qué es ClamTk
ClamTK puede instalarse desde el Centro de Software de las principales distribuciones Linux
Es cierto que casi todo lo que menciono arriba se refiere a servidores y grandes redes corporativas. También que la mayor parte de la información sobre la necesidad de instalar antivirus en Linux proviene precisamente de desarrolladores de antivirus para Linux. Déjenme citar un párrafo de una web cuyo nombre evitaremos.
No todas las soluciones antivirus son iguales. Como se ha mencionado anteriormente, los antivirus nativos para Linux son superiores a una solución basada en Windows. Pero hay grandes diferencias entre las herramientas antivirus nativas que debe tomarse el tiempo de investigar para hacer la elección correcta para su organización. Por ejemplo, las soluciones de código abierto pueden atraer a los usuarios a primera vista porque se anuncian como gratuitas. Sin embargo, los requisitos de mantenimiento y configuración son más complejos y cuestan más tiempo y esfuerzo a los equipos de seguridad. Otros factores críticos como la facilidad de uso, el rendimiento, las tasas de detección, el soporte, la escalabilidad y la gestión centralizada también deben considerarse cuidadosamente antes de tomar una decisión.
Vuelvo a la pregunta del principio del artículo ¿Los productos responden a una necesidad o la crean? Lo del aumento de las vulnerabilidades es cierto. También lo es que en equipos monousuarios donde se aplican las instalaciones frecuentemente y se instalan programas desde los repositorios oficiales, no debería haber problemas. Mucho menos si no abres archivos adjuntos.
De todas maneras, no está demás tomar precauciones y aquí entra ClamTK
ClamTK es la interfaz gráfica del antivirus de código abierto ClamAV. Este es una tecnología de código abierto para la detección de troyanos, virus, malware y otras amenazas maliciosas.
Características de ClamAV
- Escaneo usando la línea de comando o con interfaz gráfica (Instalando ClamTK)
- Filtrado de correo electrónico.
- Actualizador de base de datos de amenazas y firmas digitales con posibilidad de hacerlo mediante scripts.
- Actualización varias veces al día de la base de datos de amenazas.
- Soporte para todos los formatos de correo electrónico.
- Soporte integrado para varios formatos de archivo, incluyendo ZIP, RAR, Dmg, Tar, GZIP, BZIP2, OLE2, Cabinet, CHM, BinHex, SIS y otros.
- Soporte integrado para ejecutables ELF y archivos ejecutables portátiles empaquetados con UPX, FSG, Petite, NsPack, wwpack32, MEW, Upack y ofuscados con SUE, Y0da Cryptor y otros.
- Soporte incorporado para formatos de documentos populares, incluyendo archivos de MS Office y MacOffice, HTML, Flash, RTF y PDF.
Si algo se puede decir de ClamTK es que su interfaz es más utilitaria que bonita. Apenas las funciones ordenadas por rubro y representadas con un icono. Cuando posamos el puntero sobre cada icono nos muestra una breve explicación de las características de cada función. Sin embargo, no es demasiada intuitiva y requiere un poco de investigación o estar familiarizado con el uso de antivirus.
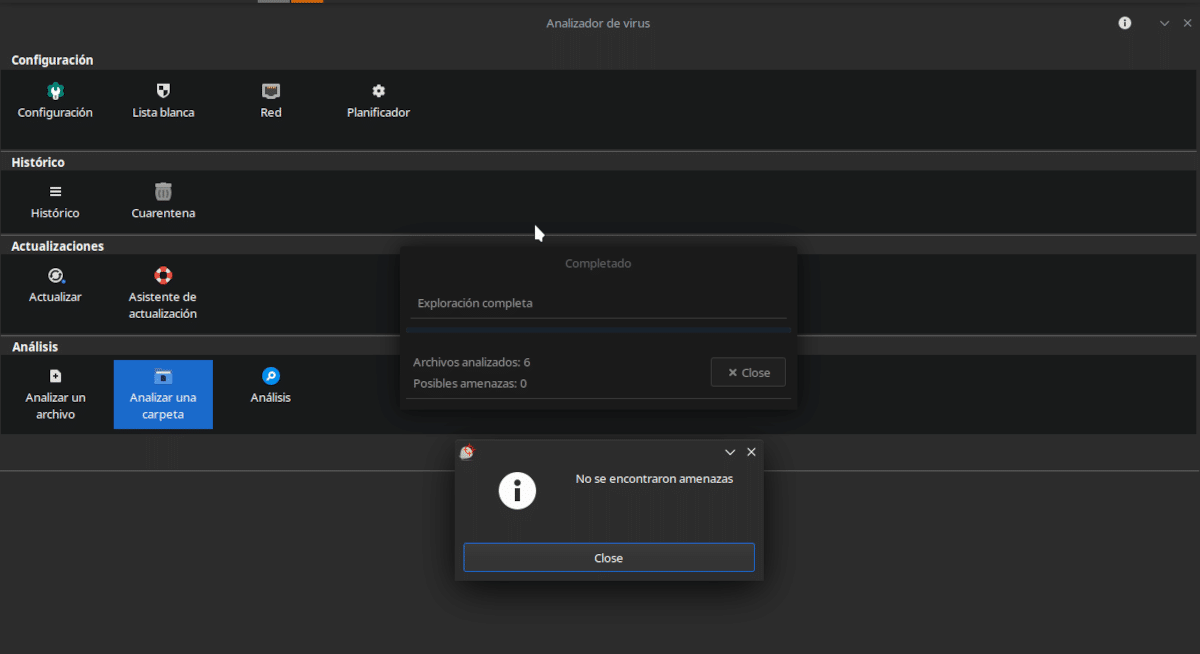
ClamTK nos permite analizar archivos y carpetas, tanto en forma manual como automática.
Las diferentes opciones de ClamTK son:
- Configuración: Determina qué y cómo se escanea.
- Lista blanca: Determina que no se considera una amenaza.
- Red: Le da a ClamAV los privilegios para acceder a Internet.
- Análisis: Determina la hora en la que se hace el análisis o se actualiza la base de datos.
- Histórico: Muestra los análisis anteriores.
- Cuarentena: Permite restaurar o eliminar los archivos aislados.
- Actualizaciones: Permite revisar las actualizaciones instaladas y el modo de actualización.
- Asistente de actualización: Permite determinar el modo como se reciben las actualizaciones.
- Analizar un archivo: ¿En serio tengo que explicarlo? Se selecciona un archivo dentro del explorador y se pulsa en OK.
- Analizar una carpeta: Lo mismo, pero con carpetas.
- Análisis: Muestra los resultados del análisis de un archivo.
En mi opinión, ClamTK (disponible en los repositorios de todas las distribuciones Linux) no aprovecha todas las capacidades de ClamAV, pero, para su uso en equipos domésticos es lo suficientemente flexible. Recordemos que cualquiera de nosotros interactúa con contenidos multimedia y abrimos archivos adjuntos que recibimos en correos electrónicos o servicios de mensajería. Aunque no infecten nuestro equipo, siempre podemos impedir que lo hagan con el de otra persona.
Yo siempre hago la comparación con el cuento de los 3 cerditos. El lobo se las arregló para entrar en las dos primeras casas. Y, si se hubiera tomado su tiempo, lo hubiera conseguido con la tercera.
from Linux Adictos https://ift.tt/uW2Paxj
via IFTTT