
(adsbygoogle = window.adsbygoogle || []).push({});
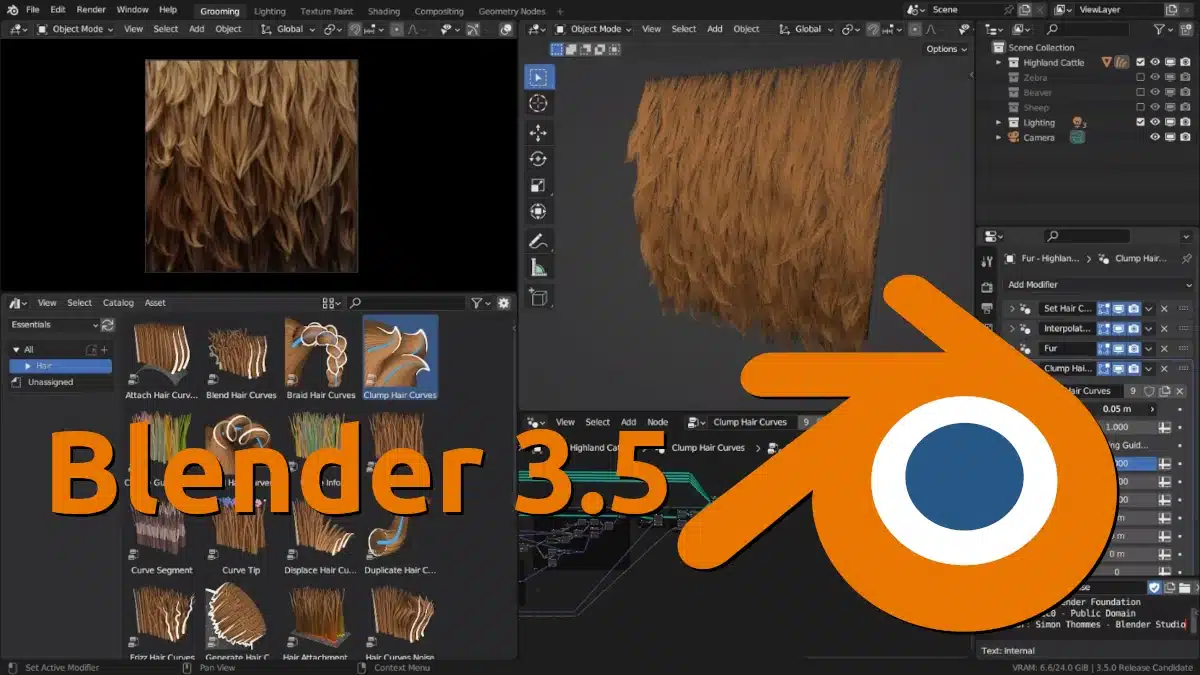
Lo sé. Sé perfectamente que este famoso programa no tiene nada que ver con la peluquería. ¿O sí? En realidad no, pero sí que tiene que ver con todo lo que se pueda agregar a una imagen, y más si es en 3D. Esta tarde, Blender Foundation ha anunciado el lanzamiento de Blender 3.5, y gran parte del protagonismo se la han llevado las mejoras que permitirán hacer que el tratamiento y el movimiento de los cabellos se vea más realistas.
Aunque el proyecto ha lanzado Blender 3.5 y pronto tiene que llegar Blender 3.6, también se están preparando para el lanzamiento de la v4.0, programada para finales de este 2023. En cuanto a la lista de novedades de la versión que ha llegado hoy, y como siempre, es bastante extensa, pero si resumimos la de la peluquería en una, la lista encoge. A continuación tenéis lo más destacado que ha llegado junto a esta versión.
(adsbygoogle = window.adsbygoogle || []).push({});
Novedades más destacadas de Blender 3.5
- Muchas mejoras relacionadas a los peinados, y para verlas con más detalle recomendamos ver el artículo original cuyo enlace tenéis encima de estas líneas.
- Nuevo nodo Image Info.
- Nuevo nodo Image input.
- Nuevo nodo Blur Attribute.
- El nodo Store Named Attribute ahora puede almacenar atributos vectoriales 2D.
- Nuevo tipo de extensión espejo para Textura de Imagen.
- Se ha cambiado el nombre de los nodos de utilidad de campo.
- Interfaz de usuario de modificadores mejorada.
- Nuevo operador Mover a Nodos.
- Arrastrar y soltar activos de grupo de nodos en la ventana gráfica.
- Nuevo nodo Interpolar Curvas.
- Recortar curvas ahora tiene entrada de selección.
- Cambios de procedimiento más rápidos.
- Mantenga pulsada la tecla Alt para desactivar la fijación automática de nodos.
- Nuevo nodo Edges to Face Groups.
- Salida de mapa UV en nodos primitivos de malla.
- Dividir aristas es ahora 2 veces más rápido.
- Visualización más rápida de muchas instancias de geometrías.
- Menú contextual mejorado en el Editor de Nodos.
- Copiar y Pegar nodos en la posición del ratón.
- Reorganizado el menú Añadir Nodos de Geometría.
- Mantenga pulsada la tecla Alt para intercambiar enlaces de nodos mientras los conecta.
- Simulación de tela un 25% más rápida mediante autocolisión
Blender 3.5, que sucede a la v3.4 que llegó con soporte oficial para Wayland, entre otras cosas, ya se puede descargar desde su página web oficial para todos los sistemas soportados. Desde allí, los usuarios de Linux podemos descargar el tarball, y en los próximos días empezará a llegar a los repositorios oficiales de la mayoría de distribuciones Linux y Flathub. Para los que prefieran el paquete snap, ya está disponible en Snapcraft.
from Linux Adictos https://ift.tt/SruoJqZ
via IFTTT









