¿Te arrepientes de haber enviado un mensaje? Aquí te vamos a decir cómo borrar mensajes en Facebook Messenger.
from Tendencias – Digital Trends Español https://ift.tt/2Cwwmip
via IFTTT

¿Te arrepientes de haber enviado un mensaje? Aquí te vamos a decir cómo borrar mensajes en Facebook Messenger.
from Tendencias – Digital Trends Español https://ift.tt/2Cwwmip
via IFTTT
The idea of monetizing DDoS attacks dates back to the 1990s. But the rise of DDoS-for-hire services and cryptocurrencies has radically changed the landscape.
from Dark Reading: https://ift.tt/3fJQnEh
via IFTTT
Ne’er-do-wells leaked personal data — including phone numbers — for some 553 million Facebook users this week. Facebook says the data was collected before 2020 when it changed things to prevent such information from being scraped from profiles. To my mind, this just reinforces the need to remove mobile phone numbers from all of your online accounts wherever feasible. Meanwhile, if you’re a Facebook product user and want to learn if your data was leaked, there are easy ways to find out.
The HaveIBeenPwned project, which collects and analyzes hundreds of database dumps containing information about billions of leaked accounts, has incorporated the data into his service. Facebook users can enter the mobile number (in international format) associated with their account and see if those digits were exposed in the new data dump (HIBP doesn’t show you any data, just gives you a yes/no on whether your data shows up). 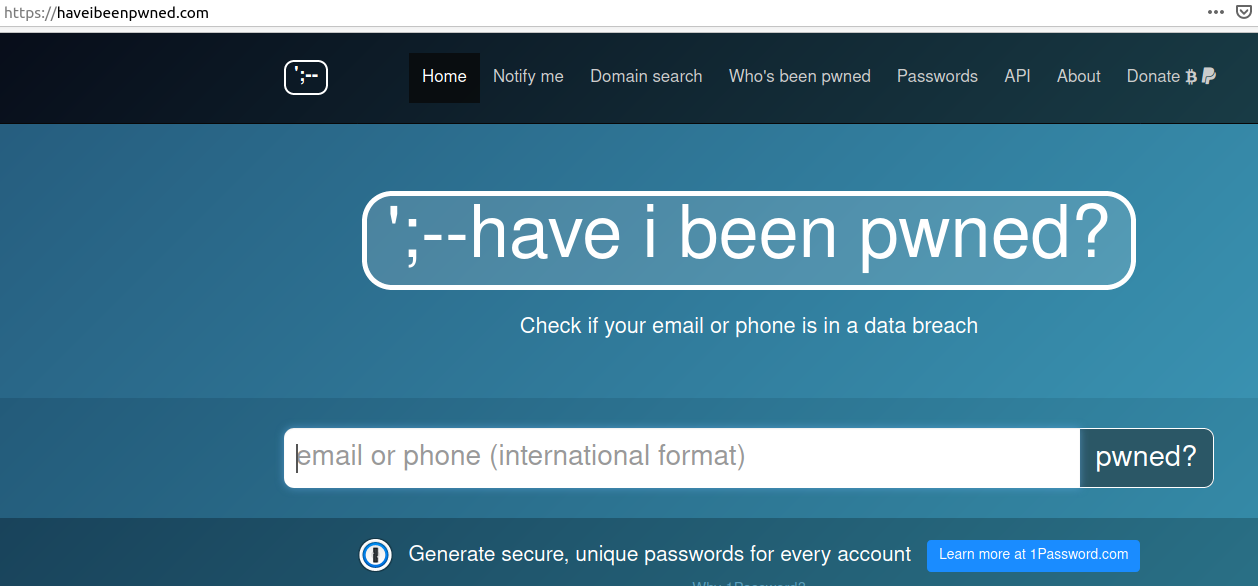
The phone number associated with my late Facebook account (which I deleted in Jan. 2020) was not in HaveIBeenPwned, but then again Facebook claims to have more than 2.7 billion active monthly users.
It appears much of this database has been kicking around the cybercrime underground in one form or another since last summer at least. According to a Jan. 14, 2021 Twitter post from Under the Breach’s Alon Gal, the 533 million Facebook accounts database was first put up for sale back in June 2020, offering Facebook profile data from 100 countries, including name, mobile number, gender, occupation, city, country, and marital status.
Under The Breach also said back in January that someone had created a Telegram bot allowing users to query the database for a low fee, and enabling people to find the phone numbers linked to a large number of Facebook accounts.
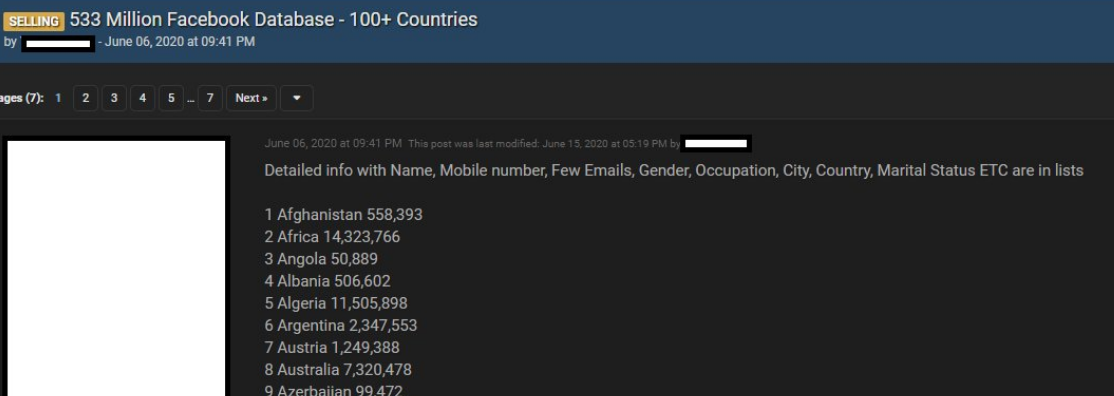
A cybercrime forum ad from June 2020 selling a database of 533 Million Facebook users. Image: @UnderTheBreach
Many people may not consider their mobile phone number to be private information, but there is a world of misery that bad guys, stalkers and creeps can visit on your life just by knowing your mobile number. Sure they could call you and harass you that way, but more likely they will see how many of your other accounts — at major email providers and social networking sites like Facebook, Twitter, Instagram, e.g. — rely on that number for password resets.
From there, the target is primed for a SIM-swapping attack, where thieves trick or bribe employees at mobile phone stores into transferring ownership of the target’s phone number to a mobile device controlled by the attackers. From there, the bad guys can reset the password of any account to which that mobile number is tied, and of course intercept any one-time tokens sent to that number for the purposes of multi-factor authentication.
Or the attackers take advantage of some other privacy and security wrinkle in the way SMS text messages are handled. Last month, a security researcher showed how easy it was to abuse services aimed at helping celebrities manage their social media profiles to intercept SMS messages for any mobile user. That weakness has supposedly been patched for all the major wireless carriers now, but it really makes you question the ongoing sanity of relying on the Internet equivalent of postcards (SMS) to securely handle quite sensitive information.
My advice has long been to remove phone numbers from your online accounts wherever you can, and avoid selecting SMS or phone calls for second factor or one-time codes. Phone numbers were never designed to be identity documents, but that’s effectively what they’ve become. It’s time we stopped letting everyone treat them that way.
Any online accounts that you value should be secured with a unique and strong password, as well as the most robust form of multi-factor authentication available. Usually, this is a mobile app like Authy or Google Authenticator that generates a one-time code. Some sites like Twitter and Facebook now support even more robust options — such as physical security keys.
Removing your phone number may be even more important for any email accounts you may have. Sign up with any service online, and it will almost certainly require you to supply an email address. In nearly all cases, the person who is in control of that address can reset the password of any associated services or accounts– merely by requesting a password reset email.
Unfortunately, many email providers still let users reset their account passwords by having a link sent via text to the phone number on file for the account. So remove the phone number as a backup for your email account, and ensure a more robust second factor is selected for all available account recovery options.
Here’s the thing: Most online services require users to supply a mobile phone number when setting up the account, but do not require the number to remain associated with the account after it is established. I advise readers to remove their phone numbers from accounts wherever possible, and to take advantage of a mobile app to generate any one-time codes for multifactor authentication.
Why did KrebsOnSecurity delete its Facebook account early last year? Sure, it might had something to do with the incessant stream of breaches, leaks and privacy betrayals by Facebook over the years. But what really bothered me were the number of people who felt comfortable sharing extraordinarily sensitive information with me on things like Facebook Messenger, all the while expecting that I can vouch for the privacy and security of that message just by virtue of my presence on the platform.
In case readers want to get in touch for any reason, my email here is krebsonsecurity at gmail dot com, or krebsonsecurity at protonmail.com. I also respond at Krebswickr on the encrypted messaging platform Wickr.
from Krebs on Security https://ift.tt/3cUGHEX
via IFTTT
The Ryuk ransomware epidemic is no accident. The cybercriminals responsible for its spread have systematically exploited weaknesses in enterprise defenses that must be addressed.
from Dark Reading: https://ift.tt/3cRNEXt
via IFTTT

Facebook ha sufrido una de las filtraciones de datos de usuarios más graves que se recuerdan. Hasta 533 millones de usuarios han visto cómo sus datos de Facebook (algunos, no todos) aparecían online en un archivo comprimido que ha recorrido diversas redes y apps de mensajería, y que finalmente ha sido convertido en una web en la que podemos comprobar si estamos o no estamos entre los afectados.
533 millones de usuarios afectados en un total de 106 países a lo largo y ancho del planeta, y hasta 11 millones de ellos con su cuenta activa desde España. Éste es un buen momento para que acudamos a esta web y verifiquemos si nuestros datos están online, de forma que podamos hacer los cambios que sean necesarios para proteger nuestra cuenta y remediar (en la medida de nuestras posibilidades) el grave error de Facebook.
Hace algún tiempo venimos escribiendo una serie de artículos sobre como instalar Mautic, una solución integral de automatización de tareas de marketing. Aunque la configuración es un poco engorrosa, a la larga termina compensando en flexibilidad y costos a soluciones privativas llave en mano como Hubspot.
El siguiente paso que tenemos que hacer (aunque en el título los haya puesto en orden inverso) es la configuración de la base de datos.
sudo mysql -u root
Puedes cambiar root por el usuario que quieras. En la ventana que se abreCREATE DATABASE mautic DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
En la línea que sigue, cambia la palabra contraseña por la contraseña que prefieras.GRANT ALL ON mautic.* TO 'root'@'localhost' IDENTIFIED BY 'contraseña';FLUSH PRIVILEGES;EXIT;
Dado que las bases de datos son una de las presas preferidas de los delincuentes informáticos, tenemos que tomar algunas precauciones de seguridad. Lo hacemos lanzando un script con este comando:sudo mysql_secure_installation
Veremos lo siguiente:
Enter current password for root (enter for none):
Pon la contraseña que elegiste en la configuración de la base de datos y pulsa Enter
Change the root password? [Y/n]
Pulsa N para dejar la contraseña actual.
Remove anonymous users? [Y/n]
Pulsa Y para eliminar a los usuarios anónimos.
Disallow root login remotely? [Y/n]
Pulsa Y para desactivar el acceso en forma remota.
Remove test database and access to it? [Y/n] y
Pulsa Y para eliminar la base de datos de prueba y su acceso (Ya sé que es redundante, pero es como aparece el texto)
Reload privilege tables now? [Y/n]
Pulsa Y para actualizar los privilegios
Si iniciaras el asistente de instalación de Mautic, te marcaría tres errores:
Los dos primeros lo solucionamos modificando cosas en el archivo php.ini
sudo nano /etc/php/7.4/apache2/php.ini
Con CTRL + W buscamos
date.timezone =
Cuando te marque esta línea
; date.timezone = «UTC»
Elimina el punto y coma y reemplaza UTC por tu zona horaria. La lista de zonas horarias admitidas las encuentras aquí.
Con CTRL + W buscamos esta línea
;cgi.fix_pathinfo=1
Cambia 1 por 0 y borra el punto y coma.
Para terminar, vuelve a pulsar CTRL + W y busca
memory_limit
Pon el valor en 512. En caso de que esté el punto y coma, borralo.
Guarda con CTRL + W
Los navegadores se están poniendo duros con el tema de seguridad, por suerte, podemos acceder en forma gratuita a un certificado para acreditar que nuestro sitio es legítimo. Dependiendo de la configuración de tu proveedor de hosting esto puede hacerse de forma automática o semiautomática.
En forma automática, se guarda una clave en el servidor y el proveedor del certificado accede a ella y comprueba que todo está correcto. En la forma seimiautomática deberrás poner esa clave en tus DNS para que le proveedor pueda comprobarla. Tu hosting te dará instrucciones de como hacerlo.
El procedimiento es el siguiente:
Instalamos la aplicaciónsudo snap install --classic certbot
Creamos el enlace simbólico para que funcione como si fuera un programa nativosudo ln -s /snap/bin/certbot /usr/bin/certbot
Lanzamos el programa para que configure el servidor.sudo certbot --apache
En caso de que te de un mensaje de error, prueba esto:sudo certbot --manual --preferred-challenges dns certonly \
-d midominio1.com \
-d www.midominio1.com \
Verás que te muestra un texto alfanumérico y un título que deberás agregar en tus DNS como registros de texto. Una vez que lo hagas. Pulsa Enter y el proveedor de certificados comprobará que eres propietario del sitio.
Ahora ya puedes abrir el navegador y poner tu nombre de dominio. Verás la página inicial de Mautic que te dice que todo está bien. Ahora puedes acceder al archivo de configuración que deberás completar con los siguientes datos: Database driver: MySQL PDO
Database Host: localhost
Database port: 3306
DB name: mautic
Database Table Prefix: Déjalo vacio
DB User: root
DB Password: La contraseña que pusiste en tu base de datos
Backup existing tables: No
from Linux Adictos https://ift.tt/3uFvRcf
via IFTTT

Los accesos directos de Windows son una pesadilla para mí. Casi cualquier aplicación que instalas te mete por defecto uno en el escritorio. Personalmente, cada vez que esto pasa lo meto en la papelera, incluso antes de que finalice la instalación. Yo quiero mi escritorio limpio, sólo dejándolo con más iconos mientras estoy haciendo un trabajo. Pero no todos los accesos directos son malos, y en Linux existen los enlaces simbólicos o Symlink que ya me gustan más.
Para empezar, estos enlaces no se generan espontáneamente y no está todo lleno de ellos. Para continuar, nos puede servir para lo que veis en la captura: enlazar todo el contenido de una carpeta multimedia a la carpeta personal. De este modo, software como VLC sólo tiene que buscar en la carpeta original para encontrar el contenido y será casi al 100% lo mismo. Y es que VLC no permite añadir una ruta extra para la biblioteca; hay que hacer que muestre su Biblioteca Multimedia, algo que no es lo mismo y, por lo menos ahora mismo, no está disponible en VLC 4.0 beta.
Para crear un Symlink, lo mejor es hacerlo con el terminal. Hay gestores de archivos que lo hacen con interfaz gráfica, pero eso sólo nos valdrá para crear un enlace a cada vez. Desde el terminal podemos arrastrar el contenido de toda una carpeta. El comando sería el siguiente:
ln -s "/ruta/de/origen" "/ruta/de/destino"
Lo bueno es que el terminal permite que le arrastremos carpetas dentro. Un ejemplo para crear el Symlink a una carpeta sería ln -s ‘/media/pablinux/Datos/Música/All That Remains’ /home/pablinux/Música, teniendo el primero las comillas porque lo he arrastrado. El comando que he usado para meter toda la carpeta de música es «un poco» más largo:
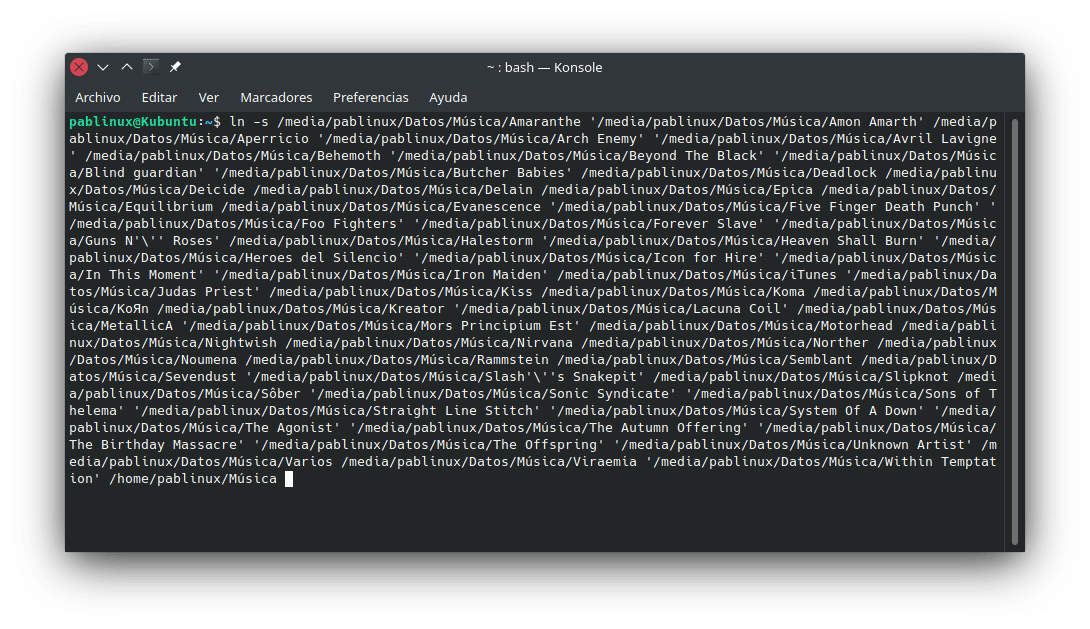
Para seleccionar todo el contenido de una ventana, lo más habitual en Linux es pulsar Ctrl + A, pero es posible que algún gestor de archivos use la combinación Ctrl + E. Una vez está todo seleccionado, lo arrastramos al terminal, indicamos la ruta de destino y presionamos Intro.
Esto puede servirnos también para «meter» algunos archivos en la carpeta /bin, más concretamente algunos que usaremos con el terminal. Por ejemplo, podemos instalar varias opciones de youtube-dl, pero sólo se actualizará al instante la que ofrecen en la página web oficial y la de su GitHub. Justo después se actualiza la que instalamos con el comando pip, pero para usarlo tenemos que instalar el paquete python3-pip y el comando para actualizar los paquetes es un poco más largo. En estos casos yo prefiero descargarme el archivo original. Actualizar si elegimos esta opción es tan sencillo como escribir youtube-dl -U, fácil de recordar en el momento veamos que funciona erráticamente.
Creando un Symlink en /bin conseguiremos que el terminal pueda lanzarlo esté donde esté. De lo contrario, no podremos lanzarlo y tendremos que arrastrar el archivo al terminal antes del enlace a descargar. Esto, arrastrarlo al terminal, es algo que sí tendremos que hacer si lo queremos actualizar, puesto que una vez lo metemos en la carpeta /bin nos da error. Quiero remarcar que meter ejecutables en la carpeta /bin puede ser peligroso y sólo se recomienda si se confía al 100% en el desarrollador .
Pero no todo es perfecto. Puede haber un par de problemas dependiendo del origen del enlace. Si estamos enlazando a la parte HDD de un disco híbrido, no se nota ninguna diferencia real. Ahora bien, algunos sistemas operativos Linux no montan esta parte automáticamente, y eso es algo que tenemos que configurar desde los ajustes. Los problemas se acentúan si el disco es externo o uno inalámbrico. Primero, en algunos casos hay que montarlo manualmente, y segundo, ahí se notará que carga los archivos. Pueden ser 2-3 segundos una película, pero es algo que hay que mencionar.
Sea lo que sea y esté donde esté el archivo original, los enlaces directos o, en este caso, Symlink pueden ser muy útiles y, teniendo en cuenta que no ocupan nada, merecen la pena.
from Linux Adictos https://ift.tt/3cU8h58
via IFTTT

Después de muchos años de una demanda realizada por parte de Oracle en contra de Google en relación con los derechos de autor sobre la API de java que es utilizada en Android, por fin se ha dado a conocer el resultado final que ha sentado los precedentes sobre este tipo de situaciones.
Y es que como recordatorio, en 2012, un juez con experiencia en programación estuvo de acuerdo con la posición de Google y admitió que el árbol de nombres que forma la API es parte de la estructura del comando: el conjunto de caracteres asociado con una función en particular. Tal conjunto de comandos es tratado por la ley de derechos de autor como no sujeto a derechos de autor, ya que la duplicación de la estructura del comando es una condición para la compatibilidad y portabilidad.
Por lo tanto, la identidad de las líneas con declaraciones y descripciones de encabezado de métodos no importa: para implementar una funcionalidad similar, los nombres de las funciones que forman la API deben coincidir, incluso si la funcionalidad en sí se implementa de manera diferente. Dado que solo hay una forma de expresar una idea o función, todos son libres de usar declaraciones idénticas y nadie puede monopolizar tales expresiones.
Oracle presentó una apelación y logró que la Corte Federal de Apelaciones de EE. UU. anulara la corte de apelaciones dictaminó que la API de Java es propiedad intelectual de Oracle. Desde entonces, Google ha cambiado de táctica y ha tratado de demostrar que la implementación de la API de Java en la plataforma Android es de uso justo y este intento se vio coronado por el éxito.
La posición de Google era que la creación de software portátil no requería una licencia de API y repetir una API para crear contrapartes funcionales interoperables era un «uso justo». Según Google, la clasificación de las API como propiedad intelectual afectará negativamente a la industria, ya que socava el desarrollo de innovaciones, y la creación de análogos funcionales compatibles de plataformas de software puede convertirse en objeto de reclamos legales.
Oracle presentó una segunda apelación y nuevamente el caso fue reexaminado a su favor. El tribunal dictaminó que el principio de «uso justo» no se aplica a Android, ya que esta plataforma es desarrollada por Google con fines egoístas, implementada no a través de la venta directa de un producto de software, sino a través del control sobre los servicios relacionados y la publicidad.
Al mismo tiempo, Google retiene el control sobre los usuarios a través de una API propietaria para interactuar con sus servicios, cuyo uso está prohibido para crear análogos funcionales, es decir, el uso de la API de Java no se limita a un uso no comercial. En respuesta, Google presentó una petición en un tribunal superior y el Tribunal Supremo de EE. UU. Volvió a revisar el tema de los derechos de propiedad intelectual de las API y falló a favor de Google.
Y ahora, la Corte Suprema de EE. UU. se pronunció sobre el caso Oracle vs Google en curso desde 2010 sobre el uso de la API de Java en la plataforma Android. Un tribunal superior se puso del lado de Google y dictaminó que la API de Java era de uso legítimo.
El tribunal acordó que el objetivo de Google era crear un sistema diferente centrado en resolver problemas para un entorno informático diferente y el desarrollo de la plataforma Android ayudó a realizar y popularizar este objetivo. La historia muestra que hay varias formas en las que la reimplementación de una interfaz puede promover el desarrollo de programas de computadora. La intención de Google ha sido lograr este tipo de progreso creativo, que es el enfoque principal de la ley de derechos de autor.
Google tomó prestadas aproximadamente 11.500 líneas de descripciones de estructura de API, que es solo el 0,4% de la implementación de API de 2.86 millones de líneas. Teniendo en cuenta el tamaño y la importancia de la parte utilizada del código, el tribunal consideró 11.500 líneas como una pequeña parte de un todo mucho mayor.
Como parte de la interfaz de programación, las cadenas copiadas están inextricablemente vinculadas por otro código (que no pertenece a Oracle) que utilizan los programadores. Google copió el fragmento de código en cuestión no por su perfección o sus beneficios funcionales, sino porque permitió a los programadores utilizar las habilidades existentes en un nuevo entorno informático para teléfonos.
from Linux Adictos https://ift.tt/3dCMyxP
via IFTTT

Hace poco los voceros de AMD dieron a conocer mediante una publicación un informe en el que se da a conocer información sobre el análisis realizado de la seguridad de la tecnología de optimización PSF (Predictive Store Forwarding) implementada en los procesadores de la serie Zen 3.
El estudio confirmó teóricamente la aplicabilidad del método de ataque Spectre-STL (Spectre-v4) a la tecnología PSF, identificado en Mayo de 2018, pero en la práctica, aún no se han encontrado plantillas de código capaces de provocar un ataque, y el peligro general se considera insignificante.
The Record citó al especialista de la Universidad de Tecnología de Graz, Daniel Gruss quien descubrió que AMD PSF puede ser vulnerable a una variedad de ataques de canal lateral, que a lo largo de los años se han desarrollado mucho.
Recordemos que el ataque Spectre-v4 (Speculative Store Bypass) se basa en restaurar datos que se han asentado en la caché del procesador luego de descartar el resultado de la ejecución especulativa de operaciones al procesar operaciones alternas de escritura y lectura usando direccionamiento indirecto.
Cuando una operación de lectura sigue a una operación de escritura (por ejemplo, mov [rbx + rcx], 0x0; mov rax, [rdx + rsi]), es posible que el desplazamiento de la dirección de lectura ya se conozca debido a operaciones similares (las operaciones de lectura se realizan mucho más a menudo y la lectura se puede hacer desde la caché) y el procesador puede leer especulativamente antes de escribir, sin esperar a que se calcule el desplazamiento de la dirección indirecta de escritura.
Esta característica permite que la instrucción de lectura acceda al valor anterior en alguna dirección mientras la operación de guardado aún está pendiente. En el caso de un error de predicción, se descartará una operación especulativa fallida, pero los rastros de su ejecución permanecerán en la caché del procesador y se pueden recuperar mediante uno de los métodos para determinar el contenido de la caché basado en el análisis de cambios en el tiempo de acceso a los datos almacenados en caché y no almacenados en caché.
Añadida a los procesadores AMD Zen 3, la tecnología PSF optimiza el método Store-To-Load-Forwarding (STLF), que realiza operaciones de lectura de forma especulativa basándose en la predicción de la relación entre las operaciones de lectura y escritura. Con el STLF clásico, el procesador realiza una operación de «carga» en los datos directamente redirigidos desde la instrucción «almacenar» anterior, sin esperar la escritura real del resultado en la memoria, pero asegurándose de que las direcciones utilizadas en la «carga» y Las instrucciones de «tienda» coinciden.
La optimización de PSF hace que la verificación de direcciones sea especulativa y realiza una operación de «carga» antes de completar el cálculo de la información de la dirección, si se ejecutó previamente un par de almacenamiento / carga manipulando una dirección. Si el pronóstico falla, el estado se revierte, pero los datos permanecen en la caché.
Un ataque a PSF solo es factible dentro del marco de privilegios del mismo nivel, cubre solo el contexto del proceso actual y está bloqueado por métodos de aislamiento del espacio de direcciones o mecanismos de caja de arena de hardware. Sin embargo, las técnicas de aislamiento de la zona de pruebas de software en los procesos pueden verse potencialmente afectadas por el problema.
El ataque representa una amenaza para sistemas como navegadores, máquinas virtuales de ejecución de código y JIT que ejecutan código de terceros dentro del mismo proceso (como resultado del ataque, el código de espacio aislado que no es de confianza puede obtener acceso a otros datos del proceso).
AMD ha proporcionado varios métodos para deshabilitar PSF completa o selectivamente, pero dado el riesgo insignificante para la mayoría de las aplicaciones, recomendó no deshabilitar esta optimización de forma predeterminada.
Para la protección selectiva de procesos que ejecutan código no confiable de forma aislada, se propone inhabilitar PSF estableciendo los bits MSR «SSBD» y «PSFD», incluso para subprocesos individuales. Para el kernel de Linux, se han preparado parches con la implementación de las opciones de línea de comandos «psfd» y «nopsfd» que controlan el encendido y apagado de PSF.
Para quienes esten interesados en poder conocer el informe, pueden consultar el siguiente enlace.
from Linux Adictos https://ift.tt/3upk2GM
via IFTTT
 Actualizar una computadora o computadora portátil tradicionalmente causa dificultades y errores por varias razones: incompatibilidad arquitectónica (diferencia en las generaciones de chipset, diferencias en el juego y generaciones de ranuras para equipos, etc.), «bloqueos de proveedor» (vinculantes a un proveedor), incompatibilidad de algunos componentes de diferentes fabricantes (por ejemplo, unidades SSD Samsung con placas base AMD AM2/AM3), etc.
Actualizar una computadora o computadora portátil tradicionalmente causa dificultades y errores por varias razones: incompatibilidad arquitectónica (diferencia en las generaciones de chipset, diferencias en el juego y generaciones de ranuras para equipos, etc.), «bloqueos de proveedor» (vinculantes a un proveedor), incompatibilidad de algunos componentes de diferentes fabricantes (por ejemplo, unidades SSD Samsung con placas base AMD AM2/AM3), etc.
Cuantas veces no has tenido que recurrir a solicitar la opinión o incluso a pedir ayuda de otro para poder conocer o tener una referencia sobre algún tipo de componente para tú o tus equipos, esto con la finalidad de poder hacer una buena compra e incluso tener la mala suerte de que dicho componente no sea compatible con tu equipo por X razon.
Es cierto que para los equipos de escritorio el problema de compatibilidad no están grande o el hecho de tener cierto riesgo de que X componente de hardware no sea reconocido, ya que este tipo de equipos suelen contar con mayor diversidad y en lo que nos basamos es en el procesador y tarjeta madre para poder conocer la compatibilidad.
Pero en el caso de los portátiles (laptops, notebooks) la cosa suele cambiar y esto es en gran medida por las restricciones que el fabricante incluye en el equipo (¿por que? lo mismo me he preguntado) y en su mayoría estas restricciones están relacionadas con la capacidad de cuanta RAM puede soportar el equipo, aun que perjures que puede soportar más.
Tocando este tema de la compatibilidad es debido a que hace pocos dias, se dio a conocer una nueva forma de buscar componentes compatibles para actualizar una computadora usando la utilidad hw-probe y la base de datos de hardware compatible del proyecto Linux-Hardware.org.
La idea de tras de esto es bastante simple, ya que se basan en las diferentes configuraciones que los usuarios comparten sobre el mismo modelo de computadora (o placa base) y con ello podemos saber que se pueden usar diferentes componentes individuales por diferentes razones: una diferencia en las configuraciones, una actualización o reparación realizada, la instalación de equipos adicionales, etc.
En consecuencia, si al menos dos personas enviaron telemetría al mismo modelo de computadora, a cada una de ellas se le puede ofrecer una lista de componentes del segundo como opciones para la actualización.
Este método no requiere el conocimiento de las especificaciones de la computadora y un conocimiento especial de la compatibilidad de los componentes individuales, ya que solo basta con que el usuario simplemente seleccione aquellos componentes que ya han sido instalados y probados por otros usuarios o proveedores en la misma computadora.
En la página de muestra de cada computadora en la base de datos, se ha agregado un botón «Buscar piezas compatibles para actualizar» para encontrar hardware compatible.
Por tanto, para buscar componentes compatibles para X ordenador, basta con crear una muestra del mismo de la forma más adecuada. Al mismo tiempo, el participante se ayuda no solo a sí mismo, sino también a otros usuarios en la actualización del equipo, quienes posteriormente buscarán componentes.
Además, es posible hacer uso de esto aun cuando se utilicen sistemas operativos que no sean Linux, ya que se puede encontrar el modelo de computadora deseado en la búsqueda o hacer una muestra usando cualquier USB Live de Linux. El programa hw-probe está disponible hoy en la mayoría de las distribuciones de Linux, así como en la mayoría de los sistemas BSD.
Para quienes estén interesados en poder hacer uso de la utilidad, tal y como se mencionó líneas más arriba, hw-probe está disponible en la mayoría de las distribuciones de Linux y si no cuentas con ella instalada, compartimos aquí tres métodos para que puedas tenerla.
La primera forma de poder instalar hw-probe en Linux es descargando la última versión estable de la AppImage de este, para ello nos vamos a dirigir al siguiente enlace y vamos a descargar la última versión estable.
Hecha la descarga vamos a abrir una terminal, nos vamos a colocar en dentro de la ruta de la carpeta donde se descargó el archivo y vamos a teclear el siguiente comando tomando en cuenta que la ver. 1.5 es la última estable:
chmod +x ./hw-probe-1.5-149-x86_64.AppImage
Y para conocer la compatibilidad de hardware tecleamos:
sudo -E ./hw-probe-1.5-149-x86_64.AppImage -all -upload
Ahora otro método es instalando el paquete flatpak de la utilidad con el siguiente comando:
flatpak install flathub org.linux_hardware.hw-probe
Mientras que el último método para instalar la utilidad es con ayuda de los paquetes Snap y podremos instalar la utilidad tecleando:
sudo snap install hw-probe
Y finalmente para conocer la compatibilidad de hardware:
sudo -E hw-probe -all -upload
from Linux Adictos https://ift.tt/31OZE5R
via IFTTT
