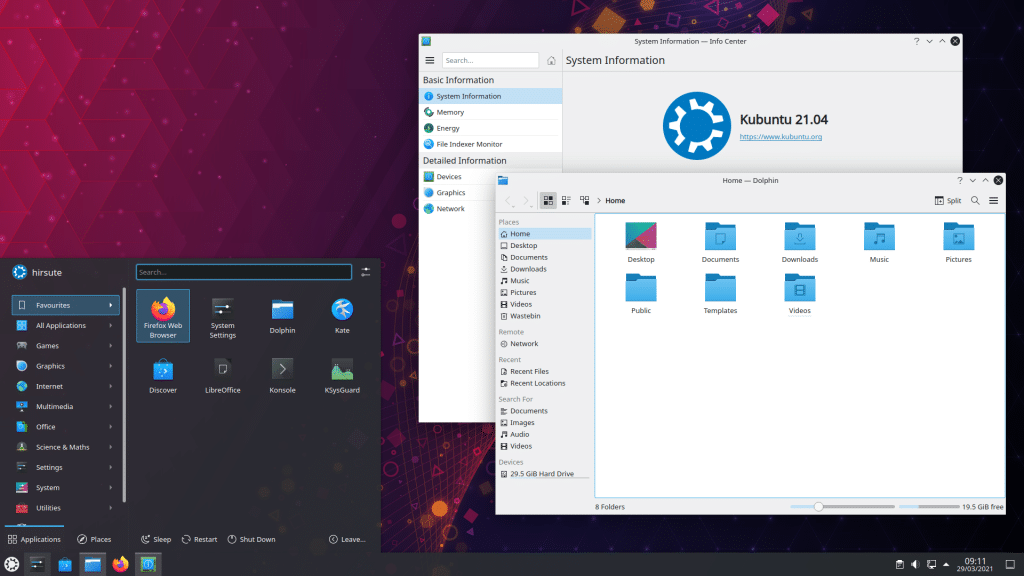
Hace ya varios dias se presentó la liberación de la nueva versión de Ubuntu 21.04 junto con todos sus sabores oficiales y siendo Kubuntu uno de estos el cual al igual que Ubuntu 21.04 y sus demás sabores, es solo una versión de transición la cual solo contará con actualizaciones durante 9 meses, es decir es una versión que solo tendrá soporte hasta enero de 2022.
Esta nueva versión de Kubuntu 21.04 Hirsute Hippo podremos encontrar muchas de las novedades que fueron introducidas en Ubuntu 21.04 de las cuales son el Kernel de Linux 5.11, integración nativa de Microsoft Active, mejoras de rendimiento, también que se volvió a habilitar una sesión en Wayland y otras cosas más.
Principales novedades de Kubuntu 21.04 Hirsute Hippo
Dentro de los cambios relacionados con esta nueva versión de Kubuntu 21.04 Hirsute Hippo podremos encontrar como principal novedad que se proporciona la actualización del conjunto de aplicaciones de escritorio KDE Plasma 5.21 y KDE Applications 20.12.3, asi como el marco Qt que se ha actualizado a la versión 5.15.2.
Y es que con KDE Applications 20.12.3 podremos encontrar que el reproductor de música predeterminado es Elisa 20.12.3 en el cual se incluye una solución para ordenar por duración.
También se destaca el nuevo lanzador de aplicaciones en el cual ahora se presentan las aplicaciones en dos paneles para facilitar la ubicación, asi como una entrada táctil mejorada, lo que aumenta la accesibilidad en todos los ámbitos.
Además, la apariencia de Plasma es mejorada en esta nueva versión, ya que se hace una nueva combinación de colores para poder presentar una apariencia unificada y más limpia.
Por otra parte, también podremos encontrar la integración de las versiones actualizadas de Krita 4.4.3 y Kdevelop 5.6.2, asi como también se continúa brindando el soporte de KDE Connect con el cual podemos vincular nuestro dispositivo móvil via WiFi y desde este podremos manejar diversos aspectos ya sea controlando aplicaciones multimedia o desde el mismo ordenador poder leer y responder mensajes.
También se destaca la inclusión del Kernel de Linux 5.11, que incluye soporte para enclaves Intel SGX, un nuevo mecanismo para interceptar llamadas al sistema, un bus auxiliar virtual, filtrado rápido de llamadas al sistema en seccomp, terminación de soporte para la arquitectura ia64, transferencia de tecnología WiMAX a rama «staging», la capacidad de encapsular SCTP en UDP.
En cuanto la paquetería básica del sistema podremos encontrar que están incluidos PulseAudio 14, BlueZ 5.56, Firefox 87, LibreOffice 7.1.2-rc2, Thunderbird 78.8.1, KDEnlive 20.12.3, VLC Media Player, entre otros mas.
Por último y no menos importante, también se destaca la sesión basada en Wayland con la cual podremos trabajar seleccionándola, ya que no está habilitada de forma predeterminada, para activarla simplemente debemos de hacerlo en la pantalla de inicio de sesión y vamos a seleccionar Wayland en lugar de X.org.
Otros de los cambios que se destacan de esta nueva versión:
- La implementación del soporte inicial para dosfstools 4
- Solución para conexiones de baja calidad en krdc
- La capacidad del visor de documentos de Okular para mostrar mejor el estado del botón «Reproducción».
Finalmente si estás interesado en poder conocer más al respecto sobre la liberación de esta nueva versión de la distribución, te invito a que puedas consultar los detalles y más al respecto sobre Kubuntu en el siguiente enlace.
Descargar e instalar Kubuntu 21.04 Hirsute Hippo
Para quienes estén interesados en poder descargar esta nueva versión de Kubuntu 21.04 Hirsute Hippo, podrán hacerlo desde los repositorios de Ubuntu, el enlace es este.
Mientras que para los que ya cuentan con una versión previa instalada (ya sea Kubuntu 20.10 o las anteriores versiones LTS tales como Kubuntu 20.04, Kubuntu 18.04 o Kubuntu 16.04) y quieren actualizar a esta nueva versión.
Lo que deben de hacer es abrir una terminal y en ella van a teclear el siguiente comando:
sudo do-release-upgrade
Si no aparece la nueva versión, sí se puede actualizar instalando
update-manager
Y usando el comando
update-manager -c -d
Es importante mencionar que si experimentas una baja velocidad en la descarga de la imagen del sistema optes por mejor descargarla por vía torrent, ya que es mucho más rápido.
Para grabar la imagen del sistema puedes hacer uso de Etcher.
from Linux Adictos https://ift.tt/3h49VDN
via IFTTT



 Se ha lanzado la nueva versión del entorno de escritorio Trinity R14.0.10, que continúa el desarrollo del código base KDE 3.5.xy Qt 3.
Se ha lanzado la nueva versión del entorno de escritorio Trinity R14.0.10, que continúa el desarrollo del código base KDE 3.5.xy Qt 3.