Te explicamos cómo utilizar un filtro de luz azul en PC, Mac y otros dispositivos para evitar problemas.
from Tendencias – Digital Trends Español https://ift.tt/2KHsmeI
via IFTTT

Te explicamos cómo utilizar un filtro de luz azul en PC, Mac y otros dispositivos para evitar problemas.
from Tendencias – Digital Trends Español https://ift.tt/2KHsmeI
via IFTTT
Podrían mantenerse en pie gracias a la condensación capilar, que fue descrita hace 150 años
from Tendencias – Digital Trends Español https://ift.tt/3qLwBLK
via IFTTT
Comparte el contenido de tu teléfono de la mejor manera: aprende a duplicar la pantalla del teléfono en el TV.
from Tendencias – Digital Trends Español https://ift.tt/2LjMMOu
via IFTTT
Este personaje de ficción buscaba hacernos reflexionar en torno al significado de la Navidad
from Tendencias – Digital Trends Español https://ift.tt/2W4BMYN
via IFTTT
Here’s where enterprises encounter challenges with cloud IAM and the best practices they should follow to correct these mistakes.
from Dark Reading: https://ift.tt/3m6lut8
via IFTTT
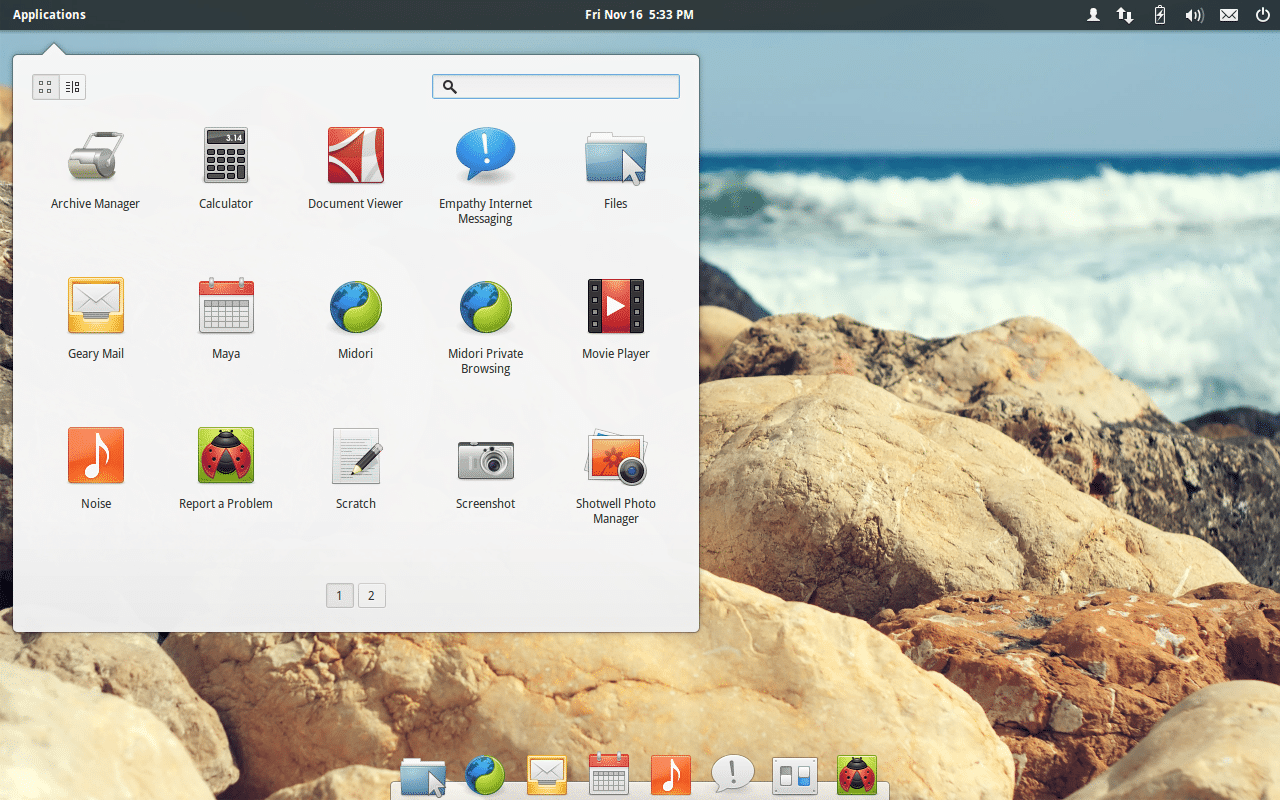
Los desarrolladores de elementaryOS han anunciado su construcción experimental para chips ARM de la serie Raspberry Pi 4. Es decir, se acerca el soporte de esta famosa distribución basada en Ubuntu, y con un aire muy «mac», a la placa SBC. Por tanto, si ya usas elementaryOS en el PC, debes saber que también lo podrás hacer en estas placas.
No es la primera vez que el proyecto elementaryOS se adentra en los dominios de ARM. Ellos ya lanzaron su sistema operativo para chips basados en ARM en agosto de este año, para que pudiera funcionar con el Pinebook Pro. Ahora, su última versión, elementary OS 5.1 «Hera» está consiguiendo soporte experimental para la Raspberry Pi 4.
Linux ya lleva tiempo funcionando en ARM, y son muchas las distribuciones que lo hacen concretamente en la Raspberry Pi, como ya sabes. Pero ahora se une esta otra, para los apasionados de Pantheon.
Realmente no es una novedad, ya sabes que durante varios años, las principales distribuciones (Arch, openSUSE, Ubuntu, Debian,…) han estado presentes en las placas Raspberry Pi. Pero eso cambió tras el lanzamiento de la Raspberry Pi 4, pese a que las nuevas especificaciones técnicas de esta SBC hacen que sea aún más fácil correr estas distros.
Ahora, poco a poco, las distros que ya tenían soporte para otras SBC, van llegando también a la Pi 4, como es el caso de elementaryOS, o Ubuntu, que hace un tiempo lanzó también su imagen oficial 20.10 para la Raspberry Pi 4.
Si te interesa probar elementaryOS en tu Raspberry Pi 4 y no quieres esperar, deberías saber que sus desarrolladores han publicado una build bajo su programa Early Access Builds. Así podrás probar ya la experiencia si quieres ser uno de los sponsors del proyecto elementaryOS. Aunque también podrás descargar esta construcción siguiendo las instrucciones que puedes encontrar en este sitio del repositorio GitHub.
Eso sí, ten en cuenta que esto es un lanzamiento experimental, por lo que no esperes maravillas. Muchas cosas funcionan correctamente, pero tal vez algunas funciones no lo hagan, o tengan algunos problemas. Por ejemplo, hay algunos problemas gráficos que deben mejorarse, así como algunos fallos con el sistema de sonido…
from Linux Adictos https://ift.tt/33W7sEf
via IFTTT
Payment card processing giant TSYS suffered a ransomware attack earlier this month. Since then reams of data stolen from the company have been posted online, with the attackers promising to publish more in the coming days. But the company says the malware did not jeopardize card data, and that the incident was limited to administrative areas of its business.

Headquartered in Columbus, Ga., Total System Services Inc. (TSYS) is the third-largest third-party payment processor for financial institutions in North America, and a major processor in Europe.
TSYS provides payment processing services, merchant services and other payment solutions, including prepaid debit cards and payroll cards. In 2019, TSYS was acquired by financial services firm Global Payments Inc. [NYSE:GPN].
On December 8, the cybercriminal gang responsible for deploying the Conti ransomware strain (also known as “Ryuk“) published more than 10 gigabytes of data that it claimed to have removed from TSYS’s networks.
Conti is one of several cybercriminal groups that maintains a blog which publishes data stolen from victims in a bid to force the negotiation of ransom payments. The gang claims the data published so far represents just 15 percent of the information it offloaded from TSYS before detonating its ransomware inside the company.
In a written response to requests for comment, TSYS said the attack did not affect systems that handle payment card processing.
“We experienced a ransomware attack involving systems that support certain corporate back office functions of a legacy TSYS merchant business,” TSYS said. “We immediately contained the suspicious activity and the business is operating normally.”
According to Conti, the “legacy” TSYS business unit hit was Cayan, an entity acquired by TSYS in 2018 that enables payments in physical stores and mobile locations, as well as e-commerce.
Conti claims prepaid card data was compromised, but TSYS says this is not the case.
“Transaction processing is conducted on separate systems, has continued without interruption and no card data was impacted,” the statement continued. “We regret any inconvenience this issue may have caused. This matter is immaterial to the company.”
TSYS declined to say whether it paid any ransom. But according to Fabian Wosar, chief technology officer at computer security firm Emsisoft, Conti typically only publishes data from victims that refuse to negotiate a ransom payment.
Some ransomware groups have shifted to demanding two separate ransom payments; one to secure a digital key that unlocks access to servers and computers held hostage by the ransomware, and a second in return for a promise not to publish or sell any stolen data. However, Conti so far has not adopted the latter tactic, Wosar said.
“Conti almost always does steal data, but we haven’t seen them negotiating for leaks and keys separately,” he explained. “For the negotiations we have seen it has always been one price for everything (keys, deletion of data, no leaks etc.).”
According to a report released last month by the Financial Services Information Sharing and Analysis Center (FS-ISAC), an industry consortium aimed at fighting cyber threats, the banking industry remains a primary target of ransomware groups. FS-ISAC said at least eight financial institutions were hit with ransomware attacks in the previous four months. The report notes that by a wide margin, Ryuk continues to be the most prolific ransomware threat targeting financial services firms.
from Krebs on Security https://ift.tt/3n6SOl6
via IFTTT

AWS anunció la semana pasada la incorporación de nuevas funciones a su plataforma Lambda. Las nuevas características introducidas por AWS Lambda incluyen soporte para el conjunto de instrucciones AVX2, soporte para imágenes de contenedores.
AWS Lambda ahora puede proporcionar funciones con almacenamiento de hasta 10 GB de memoria y 6 vCPU (procesadores virtuales), que permitirán a los desarrolladores crear funciones más intensivas en computación para obtener los recursos que necesitan.
Para quienes desconocen de AWS Lambda, deben saber que es una plataforma sin servidor impulsada por eventos proporcionada por Amazon como parte de su oferta en la nube de Amazon Web Services. La computación sin servidor no significa que no haya servidor. Esto significa que los desarrolladores ya no tienen que preocuparse por las necesidades de computación, almacenamiento y memoria, porque el proveedor de la nube, AWS en este caso, se encarga de ello.
Esto permite a los desarrolladores codificar la aplicación en lugar de implementar recursos. El objetivo de AWS Lambda, en comparación con AWS EC2 (Elastic Compute Cloud), es facilitar la creación de aplicaciones bajo demanda más pequeñas que respondan a eventos y nueva información.
AWS Lambda admite la ejecución segura de ejecutables nativos de Linux mediante un tiempo de ejecución compatible, como Node.js. Por ejemplo, el código Haskell se puede ejecutar en Lambda.
El soporte para imagen de contenedor facilita a los usuarios comerciales el uso de un conjunto coherente de herramientas para el escaneo de seguridad, la firma de códigos, etc. También permite que el tamaño máximo del paquete de código para una función se aumente a 10 GB.
Esta característica desdibuja la línea entre Lambda y los contenedores y puede ser confusa, por lo que es seguro comenzar por comprender qué es esta funcionalidad y no es. Por lo tanto, tenga en cuenta que esta función no sustituye a AWS ECS (Amazon Elastic Container Service) o AWS Fargate.
No puede ejecutar servicios de larga duración en Lambda, su código siempre está vinculado por el patrón de invocación de Lambda (es decir, solo se ejecuta cuando se llama a la función). Las llamadas de función siempre están vinculadas por la misma duración máxima de 15 minutos.
Además, la imagen del contenedor debe interactuar con la API de Lambda Runtime para solicitar eventos y enviar respuestas, al igual que un tiempo de ejecución personalizado de Lambda. Esta nueva característica le permite enviar el contenido de una función Lambda como una imagen de contenedor en lugar de un archivo zip.
También ejecuta la imagen base como está, por lo que se puede usar una imagen de Linux, como Alpine o Debian, además de que se puede utilizar una imagen base arbitraria con lo cual se puede utilizar el cliente de AWS Lambda Runtime Interface (RIC) de código abierto para que su imagen base sea compatible con la API de Lambda Runtime.
Ahora es posible empaquetar imágenes de contenedor de hasta 10 GB, que es significativamente más alto que el límite de 250 MB en el tamaño del paquete de implementación. Al igual que un entorno de ejecución de Lambda personalizado, la imagen del contenedor debe tener un archivo de arranque que interactúe con la API de ejecución de Lambda para solicitar eventos y enviar respuestas.
“A partir de hoy, puede asignar hasta 10 GB de memoria para una función Lambda. Esto representa un aumento de más de tres veces con respecto a los límites anteriores. La función Lambda asigna CPU y otros recursos de forma lineal, proporcional a la cantidad de memoria configurada. Esto significa que ahora puede tener acceso a hasta 6 vCPU en cada entorno de tiempo de ejecución ”, escribió la compañía en una publicación de blog anunciando las nuevas capacidades de AWS Lambda.
Con ello se puede especificar la ubicación del archivo de arranque mediante los parámetros «ENTRYPOINT» y «CMD» en el archivo Docker.
También se puede configurar el directorio de trabajo utilizando los parámetros «WORKDIR» y configurar las variables de entorno con el parámetro «ENV». Una vez que haya creado la imagen de Docker, debe implementar la imagen en Amazon Elastic Container Registry (ECR). Además, se debe otorgar al servicio Lambda los permisos necesarios de Administración de acceso e identidad (IAM) para acceder al repositorio y obtener la imagen del contenedor.
Fuente: https://aws.amazon.com/blogs
from Linux Adictos https://ift.tt/2W1j44p
via IFTTT
![]()
El equipo de desarrollo de Kubernetes dio a conocer hace poco la liberación de la nueva versión 1.20, versión que continúa con el trabajo de limpieza que comenzó con la versión 1.19 y presenta más de 40 características nuevas, incluidas 16 funciones mejoradas y 11 que finalmente se clasifican como estables.
El equipo prestó especial atención al desarrollo posterior de funciones importantes como los trabajos cron y el soporte CRI de Kubelet, que han permanecido en la fase alfa durante mucho tiempo. Las funciones que no muestran un progreso continuo hacia la estabilidad se marcarán como obsoletas más rápidamente en el futuro.
Uno de los principales cambios de Kubernetes 1.20 es el desuso de Docker, ya que como se menciona en el registro de cambios, la primera versión beta de 1.20 Kubernetes anunció que la compatibilidad con Docker se aplica en Kubelet en desuso y debería omitirse por completo en una de las próximas versiones.
En opinión del equipo de desarrollo, la integración de Container Runtime Interface (CRI) como interfaz de complemento para Kubelet ahora ha alcanzado el nivel de madurez requerido para poder cambiar a entornos de tiempo de ejecución de contenedores compatibles con CRI que se pueden usar sin volver a compilar.
Con ello Kubectl Debug pasa a beta, con él, los usuarios pueden inspeccionar un Pod en ejecución sin tener que reiniciarlo. Además, los usuarios ya no tienen que ingresar al contenedor para verificar los sistemas o iniciar operaciones como depurar utilidades o solicitudes de red iniciales desde el espacio de nombres de red del pod. Esta mejora elimina la dependencia de SSH para mantener y depurar nodos.
Esta función admite flujos de trabajo de depuración comunes directamente desde kubectl. Los escenarios de resolución de problemas admitidos en esta versión de kubectl:
Otro cambio importante de esta nueva versión, son las operaciones de instantáneas de volumen estable. Esta función proporciona una forma estándar de activar operaciones de instantáneas de volumen y permite a los usuarios incorporar operaciones de instantáneas de forma portátil en cualquier entorno de Kubernetes y proveedores de almacenamiento soportado.
Además, estas primitivas de instantánea de Kubernetes actúan como bloques de construcción básicos para desarrollar una funcionalidad avanzada de administración de almacenamiento a nivel empresarial para Kubernetes, incluidas las soluciones de respaldo a nivel de aplicaciones o de clúster.
Por otra parte, se destaca la limitación de PID de proceso para la estabilidad, ya que las ID de proceso son un recurso fundamental en los hosts de Linux. Es trivial alcanzar el límite de tareas sin alcanzar ningún otro límite de recursos y causar inestabilidad en una máquina host.
Los administradores necesitan mecanismos para garantizar que los pods de usuario no puedan inducir el agotamiento del pid que evite que los demonios del host se ejecuten.
Además, es importante asegurarse de que los pids estén limitados entre los pods para garantizar que tengan un impacto limitado en otras cargas de trabajo en el nodo. Después de estar habilitado de forma predeterminada durante un año, el nodo SIG cambia los límites de PID a GA enSupportNodePidsLimit y SupportPodPidsLimit.
Además en Kubernetes 1.20 la pila dual IPv4/IPv6 se ha vuelto a implementar para admitir servicios de pila dual basados en los comentarios de los usuarios y la comunidad. Esto permite que las direcciones IP del clúster de servicios IPv4 e IPv6 se asignen a un solo servicio, y también permite que un servicio pase de una pila de IP única a una pila de IP doble y viceversa.
Finalmente, si quieres conocer más al respecto sobre esta nueva versión, puedes consultar los detalles en el siguiente enlace.
from Linux Adictos https://ift.tt/3a0XGEC
via IFTTT
Demands of the “new normal” won’t stop the majority of poll-takers from mastering new skills.
from Dark Reading: https://ift.tt/3873DNV
via IFTTT
